Nvidia et AMD travaillent durent autour de leurs prochaines architectures graphiques. Nommées respectivement Ada Lovelace et RDNA 4, elles ont un objectif en commun, celui de franchir la barre symbolique des 100 TFLOPs en FP32.
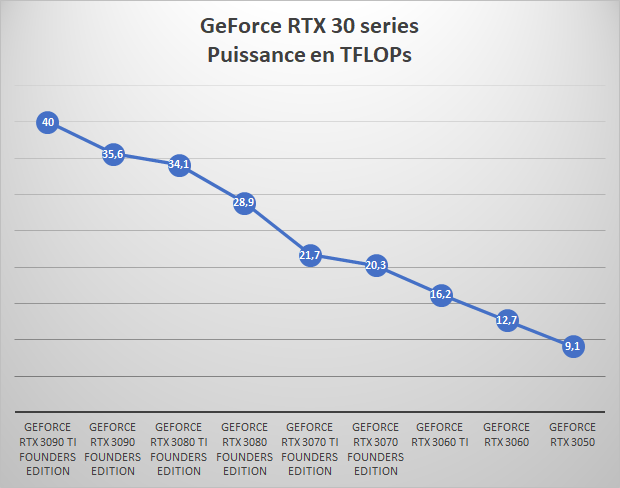

Pour repositionner ce chiffre la récente GeForce RTX 3090 Ti propose une puissance théorique de 40 TFLOPS contre 23 TFLOPs pour la Radeon RX 6900 XT. Il est intéressant de noter que la barre des 1 TFLOP a été franchie en 2008 par AMD grâce au « RV770 ». Si tout se passe comme prévu, 14 ans auront été nécessaire pour multiplier ce chiffre par 100.
GPUs AD102 de Nvidia et Navi 21 d’AMD, en route vers les 100 TFLOPs
Le GPU phare d’« Ada Lovelace », l’AD102 devrait assurer cette puissance grâce à ses 144 SM donnant vie à 18 432 cœurs CUDA. Du coté d’AMD l’offre vitre basée sur l’architecture RDNA3 sera le GPU Navi 31 qui est censé proposer du 92 TFLOPs ce qui avec quelques ajustements de fréquence atteindra probablement les 100 TFLOPs. Pour parvenir à cette prouesse Navi 31 devrait tripler le nombre d’unités de calcul par rapport à son prédécesseur soit s’équiper de 15 360 processeurs de flux.
Que nous parlions d’AD102 et de Navi 31 dans les deux cas une fabrication issue du processus N5 de TSMC (gravure en 5 nm EUV) est prévue. Le lancement de tout ce beau monde est prévu avec la fin de l’année.
| GPU (rumeurs) | AD102 | NAVI 31 |
| Nom de code | Ada Lovelace | RDNA 3 |
| Vitrine | GeForce RTX 4090 | Radeon RX 7900 |
| Finesse de gravure | TSMC 4N | TSMC 5nm+ TSMC 6nm |
| GPU Package | Monolithique | MCD |
| GPU Clusters | 144 SM | 120 unités de calcul (CU) 240 unités de calcul (au total) |
| Cœurs | 18 432 Cœurs CUDA | 15 360 SP |
| Fréquence max | ~2,85 GHz | ~3,0 GHz |
| Puissance FP32 | ~105 TFLOPs | ~92 TFLOPs |
| Type de mémoire | GDDR6X | GDDR6 |
| Capacité de mémoire | 24 Go | 32 Go |
| Bus mémoire | 384-bit | 256-bit |
| Vitesses de mémoire | ~21 Gbit/s | ~18 Gbit/s |
| Cache | Cache L2 de 96 Mo | Infinity Cache de 512 Mo |
| TBP | ~600 W | ~500 W |
| Date de lancement | T4 2022 | T4 2022 |
“Il est intéressant de de noter que la barre des 1 TFLOP a été franchie
en 2088 par AMD grâce au *RV770*.”
Tiens un voyageur du temps qui rend visite aux péons de 2022… 😀
Comme le dit l’adage, sans maîtrise la puissance n’est rien!
Atteindre les 100 Tflop/s est une chose cependant pouvoir y accéder
sur une quantité limitée de triangles en est une autre.
Par ailleurs, le calcul FP32 n’a d’intérêt que pour le traitement
de textures donc pas de quoi révolutionner la géométrie des jeux
vidéos.
Autant pour moi j’ai confondu FP16 et FP32. :-/
Ceci dit le reste me semble toujours valide puisque la faible
complexité d’une scène 3D peut très facilement mettre en défaut
cette débauche de transistors du fait de l’étalement de la
puissance.
Je viens de voir que le cray II, supercalculateur mythique et inapprochable de 1985, utilisé par l’armée developpait 1,9 GF.
Maintenant on a 50.000 fois plus (si je ne me trompe pas) @home, preuve que l’on fait vraiment pas grand chose avec ce que l’on à 😉
Rassure-toi l’armée n’en fait pas plus avec son équipement militaire
dont les commandes servent bien souvent à subventionner des entreprises
ou laboratoires de recherche.
Par ailleurs, un supercalculateur a besoin de “superlogiciel” dont le
coût de conception est pharaonique.